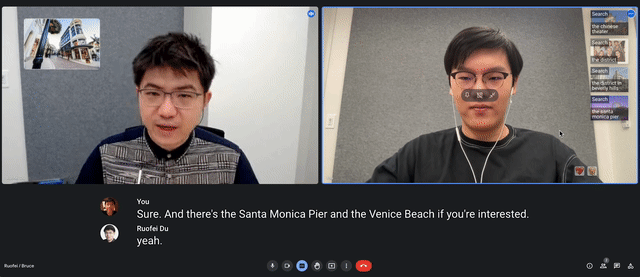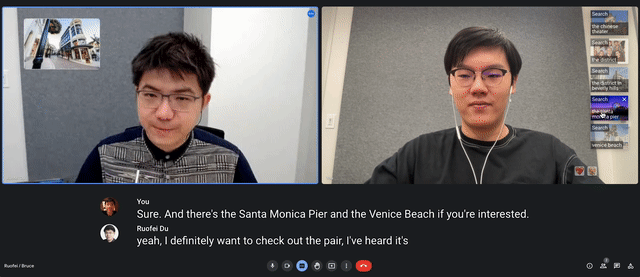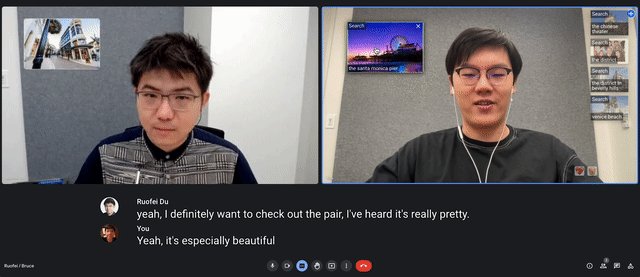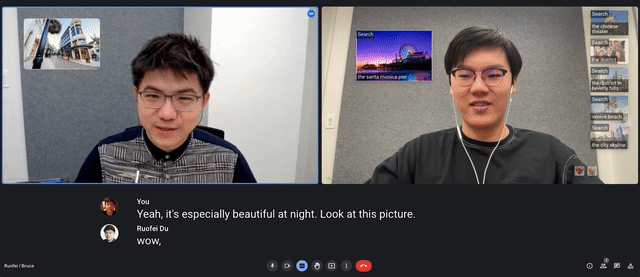
Video conferencing solutions like Zoom, Google Meet, and Microsoft Teams are becoming increasingly popular for facilitating conversations, and recent advancements such as live captioning help people better understand each other. We believe that the addition of visuals based on the context of conversations could further improve comprehension of complex or unfamiliar concepts. To explore the potential of such capabilities, we conducted a formative study through remote interviews (N=10) and crowdsourced a dataset of over 1500 sentence-visual pairs across a wide range of contexts. These insights informed Visual Captions, a real-time system that integrates with a video conferencing platform to enrich verbal communication. Visual Captions leverages a fine-tuned large language model to proactively suggest relevant visuals in open-vocabulary conversations. We present findings from a lab study (N=26) and an in-the-wild case study (N=10), demonstrating how Visual Captions can help improve communication through visual augmentation in various scenarios.
@inproceedings{10.1145/3544548.3581566,
author = {Liu, Xingyu Bruce and Kirilyuk, Vladimir and Yuan, Xiuxiu and Olwal, Alex and Chi, Peggy and Chen, Xiang 'Anthony' and Du, Ruofei},
title = {Visual Captions: Augmenting Verbal Communication with On-the-fly Visuals},
year = {2023},
isbn = {9781450394215},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3544548.3581566},
doi = {10.1145/3544548.3581566},
booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems},
articleno = {108},
numpages = {20},
keywords = {AI agent, augmented communication, augmented reality, collaborative work, dataset, large language models, online meeting, text-to-visual, video-mediated communication},
location = {Hamburg , Germany },
series = {CHI '23}
}