publications
ACM CHI and ACM UIST are top conferences for technical HCI work.
2024
2023
-
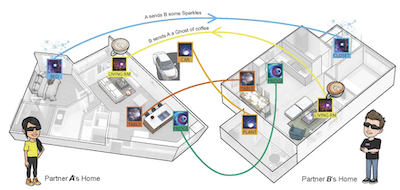
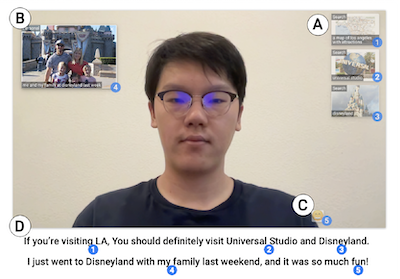
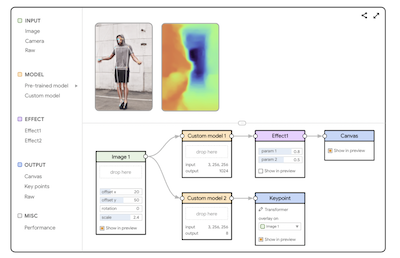
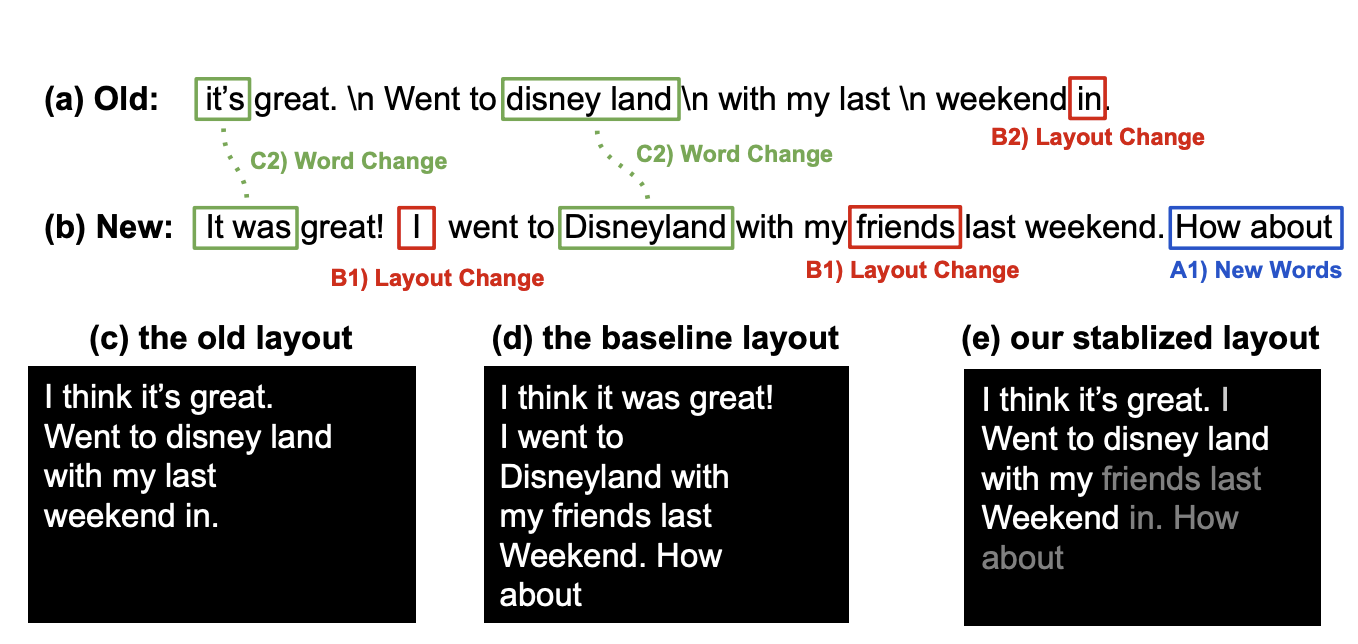
 Experiencing Visual Captions: Augmented Communication with Real-Time Visuals Using Large Language ModelsIn Adjunct Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23 Adjunct)
Experiencing Visual Captions: Augmented Communication with Real-Time Visuals Using Large Language ModelsIn Adjunct Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST ’23 Adjunct) -